Entre muitas pesquisas de empresas de tecnologia no ramo de imagens geradas por inteligência artificial, uma iniciativa open-source (de código aberto, colaborativa) chamada Stable Diffusion se destacou por sua versatilidade, variedade de adaptações criadas na comunidade, e fácil acesso para pessoas que tenham um computador compatível.
Embora a tecnologia ainda só funcione em inglês (no momento) e exija uma enorme quantidade de processamento gráfico, ela já é acessível aos que possuem computadores com placas de vídeo RTX e/ou com muita VRAM – que é o caso de muitas máquinas gamer.
A surpreendente evolução em menos de 1 ano
Embora seja pesquisada há mais tempo, a geração de imagens por AI se tornou popular quando foi disponibilizada para o público a ferramenta DALL-E Mini que gerava imagens a partir de um texto em linguagem natural, também chamado “prompt”.
Por exemplo, apenas com o prompt “Steve Jobs delivering pizza” (Steve Jobs entregando pizza) foi possível gerar a imagem abaixo. Considerando que a máquina associa palavras a imagens da internet para criar algo novo, o resultado, embora estranho ou deformado, era compreensível.

Hoje, sistemas como o DALL-E 2, MidJourney ou o Stable Diffusion a partir do mesmo comando podem gerar resultados como esse:

Isso faz com que você possa soltar a sua imaginação gerando fotos ou pinturas com o estilo do seu autor favorito, criando estilos novos, designando o tipo de iluminação ou contexto.
Na prática, com Stable Diffusion você pode criar uma imagem do Steve Jobs entregando pizza, entender como ela seria se fosse um filme da Pixar, uma pintura a mão, um anúncio publicitário ou uma pintura de Romero Britto. As possibilidades são infinitas:

Afinal, como “pensa” a AI?
A difusão estável é justamente a máquina partir de um ruído aleatório e “puxar” características de outras imagens. Milhões de referências são consultadas e a média de como palavras se relacionam com características da imagem. Cada pixel é calculado para se aproximar desta média. Embora para a máquina tudo seja um gigantesco cálculo matemático mixando pedaços de milhões de imagens, para nós a abstração humana é: Steve Jobs e Pizza.
A máquina não sabe o que faz, por isso também pode expressar vieses, preconceitos e equívocos humanos que contaminam, em média, as amostras gerais da internet. Mas também expressa conceitos subjetivos e surreais, tais como a morte, Deus, solidão, raiva, amor e tantos outros.
Tais conceitos são imageticamente gerados pois a AI foi “alimentada” com imagens que continham essas “tags” ou, em outras palavras, pedaços de informação gerados por seres humanos. Tal processo também é chamado de “treinamento”, inclusive, em sua última atualização, o usuário Yacben, (link), modificou o software para que fosse possível que o usuário-final realizasse os treinamentos personalizados.
No exemplo a seguir, Dave James do portal PC GAMER treinou o Stable Diffusion para “entender” o estilo gráfico do seu falecido tio. (link)
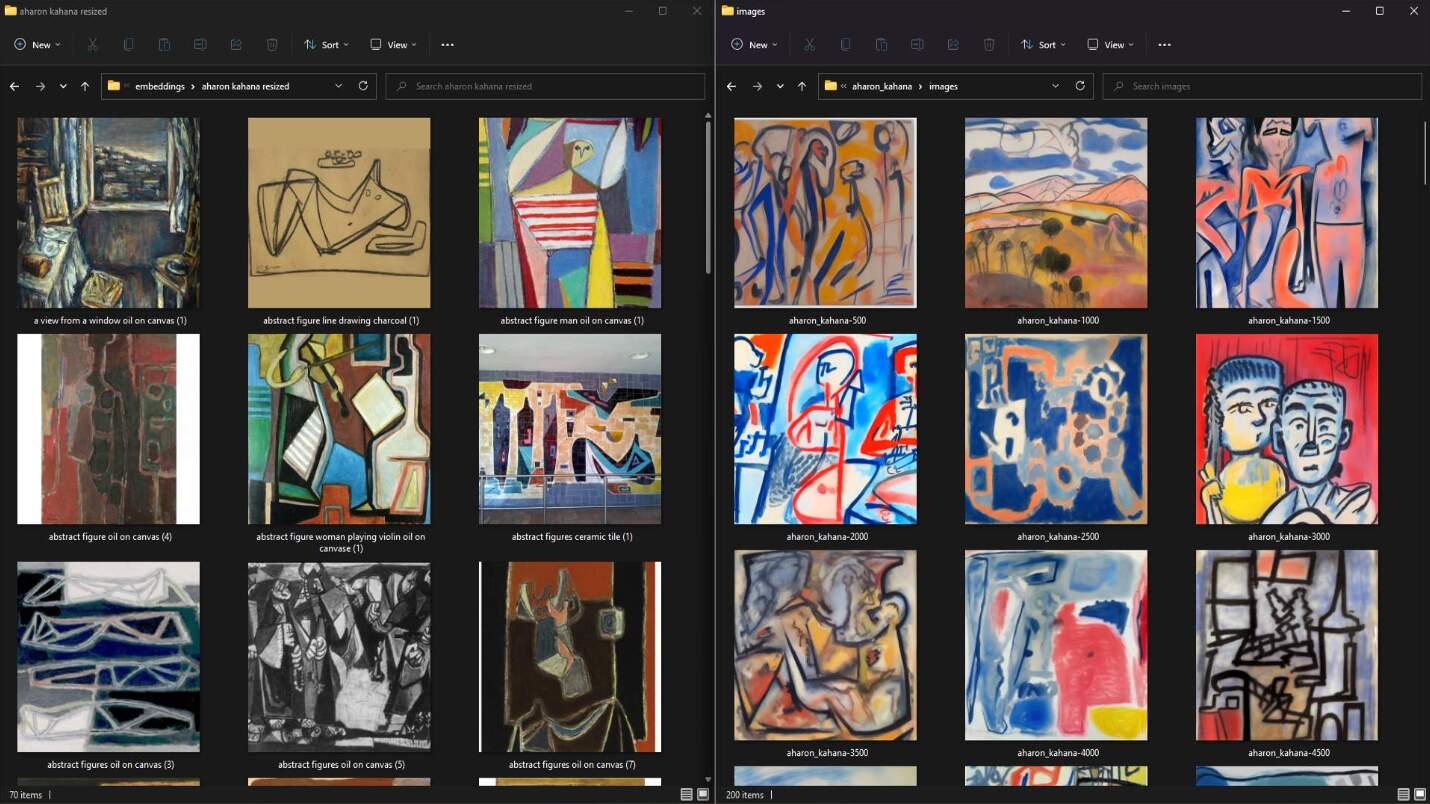
Assim como nós, as AIs são criativas a partir das referências às quais têm acesso.
Possíveis aplicações
A capacidade criativa da AI a partir de textos é impressionante, mas não é seu único recurso que poderá mudar o mercado de ilustração, seja como um poder maior na mão dos artistas, ou a ilustração se tornando mais acessível para quem não é artista. Um de seus recursos mais chamativos é a capacidade de reinterpretar imagens existentes.
O usuário “Ringerill” publicou no Reddit uma reinterpretação da Monalisa que fez dividindo a obra em 9 partes, pedindo para que a AI reinterpretasse a cena como uma guerra, e voltou a juntar as imagens gerando este resultado impressionante e criativo:

Nossos testes
Neste sentido, utilizamos o Stable Diffusion para reproduzir nosso logotipo como uma maleta azul realista. Ou nosso estúdio como um estúdio futurista.


Eu também decidi usar o Stable Diffusion para evitar a academia por mais tempo.

Aprendendo a escrever prompts
A capacidade da AI de criar artes realistas ou surreais, e reinterpretações com base em prompts específicos, abre o ramo para um novo campo de estudo nas artes: a “engenharia de prompts” – onde as pessoas buscam aprender a “conversar” com a máquina para estabelecer prioridades na criação de suas artes, evitar deformações, evoluir de uma variação para a outra e buscar resultados super específicos como:
Cães realistas, belas mãos, paisagens surreais ou controle da pressão das pinceladas de uma pintura e até reflexos ou a posição do sol em uma imagem realista. Você pode se especializar em retratos, imagens aéreas, imagens térmicas, Gopro, manipulação da luz, neon e literalmente infinitas outras possibilidades ou artistas.
Assim a própria comunidade discute e já lançou seu primeiro livro sobre o assunto.
AIs geradoras de vídeos
Naturalmente, após a criação das imagens os desenvolvedores focaram seus esforços no próximo passo: a geração de vídeos. Uma vez que um vídeo é, em última instância, uma mera sequência de imagens.
1/ Using AI to generate fashion
After a bunch of experimentation I finally got DALL-E to work for video by combining it with a few other AI tools
See below for my workflow –#dalle2 #dalle #AIart #ArtificialIntelligence #digitalfashion #virtualfashion pic.twitter.com/x3zP3fIp4G
— Karen X. Cheng (@karenxcheng) August 30, 2022
O Google já publicou sua pesquisa de vídeo gerado por AI, e embora pareçam um pouco trêmulos ou instáveis, é preciso lembrar o quanto a tecnologia é recente e o quanto já evoluiu.
https://imagen.research.google/video/
Consegue imaginar como isso se dará em 2 ou 3 anos?
Como isso afetará o nosso dia a dia?
Uma bela foto publicitária já pode ser gerada a partir de uma simples foto de celular. Uma montagem para parecer forte e musculoso que hoje já pode ser feita no Stable Diffusion em 30 segundos sem conhecimento de Photoshop, conforme já demonstrado – e em breve poderemos produzir esse tipo de efeito em vídeos sem domínio de pós-produção e efeitos visuais.
Os governos já se atentam aos potenciais riscos do uso indiscriminado destas tecnologias na geração de cenas violentas, sexuais, criminosas, uso de rostos de terceiros ou até mesmo estilos de artistas populares.
As relações de propriedade intelectual terão que ser repensadas a partir deste novo paradigma. Mas, por outro lado, a imaginação humana poderá estar numa tela com cada vez mais velocidade e facilidade.
Embora numa versão mais limitada, você pode testar a ferramenta online, sem precisar de um computador gamer. Vamos tentar? https://huggingface.co/spaces/stabilityai/stable-diffusion
E você, o que acha de tudo isso? Deixe o seu comentário!
Quer saber mais dicas sobre o mundo dos negócios?
Então siga o WorkStars nas redes sociais LinkedIn | Instagram | Youtube | B2B para Startups